다른 사람들이 설명을 너무 어렵게 해놔서 좀 쉽게 쉽게 하려고 합니다
(구라 입니다 다 쓰고 직접 읽어보니 어렵네요)
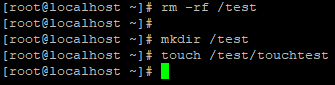
/test 디렉터리가 있다면 우선 rm -rf 해서 /test 디렉터리를 지워주고 다시 만들어주자
touch 명령어로 touchtest라는 빈 파일도 만들어주자
# > grep
파일 내용에서 문자열( [pattern] )을 검색
#>grep [option] [pattern] [path]
-v [pattern]이 존재하지 않는 라인만 출력
-i 대소문자 구별 X
-n 줄 번호를 같이 출력
-c 라인 개수 출력
간단하게 말해서 grep 란 "검색"이라고 생각하면 편하다 내가 특정 파일의 특정 부분만 찾고 싶다고 할 때 그 부분만 나타내 주는 게 grep 명령어이다

touchtest라는 빈 파일을 편집해서

막 적고 끝에 user라고 적은다음 저장하고 나오자
grep 명령어를 사용하기 전에 정규 표현식이라는 걸 알아보자 별로 어렵지 않다
[정규 표현식]
^[문자열] [문자열]로 시작하는 라인
[문자열]$ [문자열]로 끝나는 라인
. 임의의 문자
[] 문자 집합
[^] NOT
어디에 검색할 때 또는 파일을 작성할 때 쓰이는 도우미? 들이다
grep 명령어는 "검색"이라고 한다고 했다 그 검색어들을 찾을 땐 검색하고 싶은 단어나 문자를 "" 큰따옴표 안에 넣어야 한다 아까 touchtest 파일을 통해 알아보자

grep "user" /test/touchtest
스크린 샷만봐도 어떤 명령어인지 감이온다 아래 예시를 몇개 더 봐보자

문자 앞에 ^를 넣으면 ^로 시작하는 문자열을 보여줘!

문자 끝에 $를 넣으면 $로 끝나는 문자열을 보여줘!

[] 안에 문자를 넣으면 그 문자가 들어간 걸 보여줘!
[] 안에 ^나$ 을 넣으면 NOT 이 된다.
a를 제외하고 보여준다
다중 명령어
1) ; 명령을 차례대로 수행
--> 앞의 명령어 수행 결과에 영향을 받지 않음
2) && 명령을 차례대로 수행 (and)
--> 수행 결과가 실패 면 더 이상 진행 X
3) || 명령을 차례대로 수행 (or)
--> 수행 결과가 성공일 때까지 진행
4) | 프로세스와 프로세스 간의 연결
다음은 shell(터미널)에서 명령어를 사용할 때 활용할 수 있는 다중 명령어 옵션들을 알아보자
1. ( ; )

원래는 mkdir /test2 따로 touch /test/touchtest2 따로 적었어야 하는데 가운데 ;를 넣으니 한 줄에 두 가지 명령어를 수행할 수 있습니다.
2. ( && ) and

&&은 and라고 해석하면 됩니다 두 가지 명령을 실행하는데 앞에 명령어가 실패하면 뒤에 명령어는 실행조차 하지 않습니다
3. ( || ) or

|| 은 or이라고 생각하시면 됩니다 수행 결과가 성공할 때까지 계속 진행합니다
/test /test2 두 개는 이미 있는 파일이라 생성이 안되지만 test3는 없는 파일입니다

# ls -l / | grep "test" 라는 저번에 배운 grep를 활용해 최상위 디렉터리 위에 test라는 파일을 전부 찾아보았습니다 test3 가 생성된 게 보이네요!
4. ( | ) 파이프 / 정말 자주 사용함 별 5개
파이프는 두 개의 명령어를 동시에 사용할 때 자주 씁니다 위에 ls -l / | grep "test" 같이 ls -l /에서 test라는 걸 찾아줘!라고 해석하면 됩니다 /etc 디렉터리에는 아주 많은 파일과 디렉터리들이 존재합니다 이걸 파이프를 이용해서

이렇게 more 명령어와 같이 사용하시면
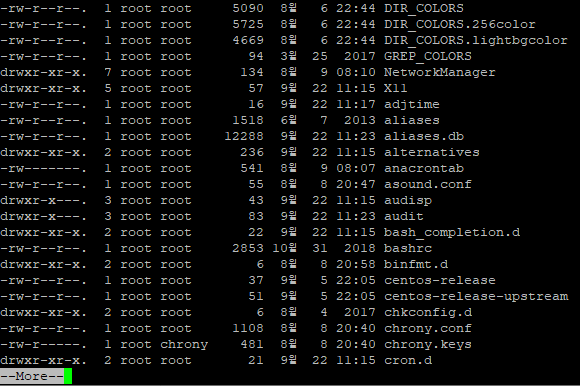
ls -l /etc 명령어를 more로 볼 수 있게 됩니다.
간단하게 말해 파이프란 A | B 로 되어 있으면 A를 실행할게 B를 사용해서 라고 이해하시면 됩니다 A와B의 조합에 따라서 각양 각색이긴 하지만 이렇게 이해하시면 편합니다
=======================================================
파이프와 사용하면 좋은 명령어들
# > sort
문자 또는 숫자를 기준으로 정렬하여 출력
#>sort [option] [path]
-n 숫자를 기준
-r 역 정렬
-u 중복 라인 제거
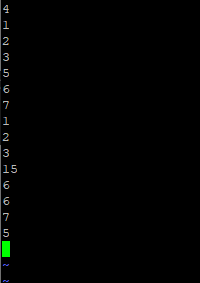
아까 만들었던 /test/touchtest 파일을 편집해서 숫자를 순서와 상관없이 아무렇게나 적어보자
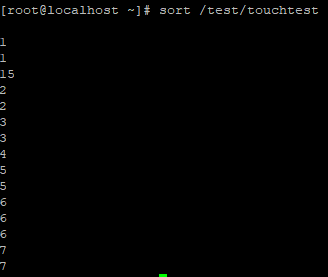
그리고 sort 명령어를 사용하면 제일 앞자리 숫자를 기준으로 1234 순서대로 정렬되어서 출력된 걸 볼 수 있다
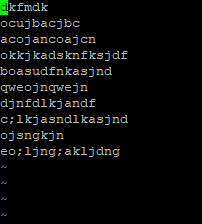
이번엔 영어로 해서 뒤죽박죽 섞어보자
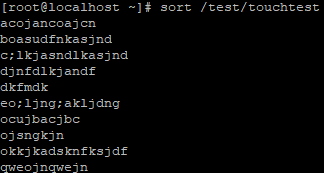
역시나 맨 앞자리 기준으로 abcd 순서대로 정렬되어서 보여준다
(옵션은 써져 있으니 한 번씩 직접 해보시는 걸 추천드립니다) (절대 귀찮아서 그러는 거 아님)
# > uniq
중복되는 행을 필터링 한다.
#>uniq [option] [path] ( #>sort [path] | uniq [option] )
-d 중복 라인만 출력
-u 중복되지 않은 라인만 출력
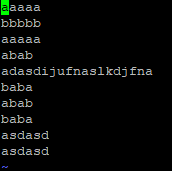
/test/touchtest 파일을 편집

보통 sort 와 파이프로 같이 사용한다 sort /test/touchtest | uniq -u로 사용하면
정렬도 해줌과 동시에 중복되지 않은 라인만 출력할 수 있다
(사실 이 외엔 잘.. 사용하지 않는다 이 포스팅을 쓰기 전에 저런 명령어가 있었나..? 하고 까먹고 있었다..)
# > cut
필드 잘라내기
#>cut [option] [path]
-c [num] [num] 번째 문자
-f [num] [num] 번째 필드
-d [구분자] ( default tab)
cut 은 알고 있으면 꽤나 사용하기 좋은 명령어이다
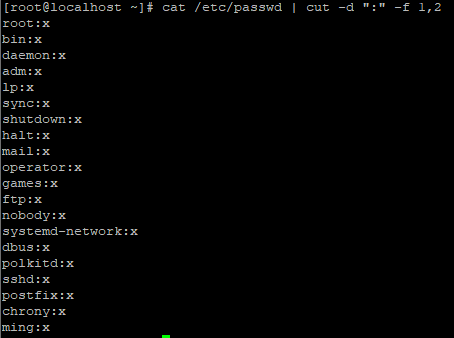
명령어를 해석해보자
# > cat /etc/passwd | cut -d ":" -f 1,2
cat /etc/passwd 파일을 읽어온다
| 파이프와 연결하여 동시에 사용
cut -d 구분자 "" 큰따옴표 안에 있는 문자를 기준으로 ":"
-f 1,2 1번 필드와 2번 필드만 보여줘라
이런 식으로 사용할 수 있습니다 따옴표를 기준으로 나누어서 볼 수 있게 해주기도 하죠
여러 가지로 사용할 수 있습니다
# > awk
<, <= , > , >= , == , !=
#>awk [option] '[조건식]{print [출력할 필드($[num]) or 문자열]}' [path]
-F [구분자]
[shell] 쿼터
1) ' 문자열을 표현할 때 사용( 메타 문자 X)=(변수 해석 불가)
- ex) 'my name' (my name이라는 문자)
2) " 문자열을 표현할 때 사용( 메타 문자 O) =(변수 해석 가능)
- ex) "$num1" (num1 변수의 값을 의미)
3) \ 문자로 표현 (쿼터 앞에 붙여주면 일반 문자로 표현해줍니다)
-ex)
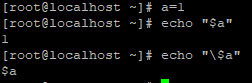
a에 1을 대입하고 echo 명령어로 메타 문자를 확인할 수 있는 큰따옴표 안에 "$a" a 변수를 넣고 1을 출력하지만 \ 문자 앞에선 일반 문자로 변환해줌.
($은 다음에 따로 설명하겠습니다.)
'Linux 2급' 카테고리의 다른 글
| 리눅스 지역변수,전역변수,알리아스 (Alias) (0) | 2023.11.02 |
|---|---|
| 리눅스 권한 (umask, chmod), symbolic (심볼릭링크x) (0) | 2023.11.02 |
| 리눅스의 꽃 vi 편집기 (vi editor) (1) | 2023.11.02 |
| 리눅스 기본 명령어 (touch, cat, head, tail, more, less, file, stat, cp, mv, rm, tty) 쉽게 배우기 (0) | 2022.06.29 |
| 리눅스 기본 명령어 쉽게 이해하기 (pwd, ls, cd, mkdir, rmdir) 리눅스 기초 (0) | 2022.06.20 |



